在过去一年中,我们与各行各业数十个团队合作,帮助他们基于大型语言模型 ( LLM ) 构建 Agent。我们发现,最成功的实现并不依赖复杂的框架或专业化的库,而是使用了简单且可组合的模式。
在本文中,我们将分享与客户合作以及我们自身构建 Agent 时所积累的经验,并为开发者提供一些构建高效 Agent 的实用建议。
什么是 Agent?
“Agent”这个词有多种定义。有些客户将其定义为完全自主的系统,可以在较长时间内独立运行,使用各种工具完成复杂任务。另一些客户则用该词来指代更具流程化的实现,它们按照预先定义的工作流执行。
在 Anthropic,我们将以上所有变化形式都归类为 Agentic 系统,但在结构上会区分工作流 ( workflow ) 与 Agent:
- 工作流 是指通过预定义的代码路径来编排 LLM 与工具的系统。
- Agent 则是指由 LLM 动态地指挥自己的流程和工具使用方式的系统,始终由 LLM 来掌控完成任务的方式。
下文中,我们将详细探讨这两种 Agentic 系统。在附录 1(“Agent 在实践中的应用”)中,我们将描述两个客户在这些系统上取得显著成效的典型场景。
何时(以及何时不)使用 Agent
Authropic强烈建议:在使用 LLM 构建应用时,我们建议从最简单的方案着手,只有在需要时才增加复杂度。这意味着很多时候根本不需要构建 Agentic 系统。Agentic 系统通常会牺牲一定的延迟和成本来获取更好的任务性能,你需要考虑这种取舍是否值得。
工作流能够在明确的任务中提供可预测性与一致性,而在需要灵活性和模型驱动决策的大规模场景下,Agent 则是更好的选择,但这会增加额外的复杂度。
然而,对于很多应用来说,只要能结合检索 ( retrieval ) 和上下文示例来优化一次性 LLM 调用,通常就已足够。
简单来说:
- 选择工作流:当任务明确定义,需要可预测性和一致性
- 选择Agent:任务需要灵活性或任务需要模型驱动的动态决策
何时以及如何使用框架
目前有许多框架能够让 Agentic 系统的实现更加容易,包括:
- LangChain 的 LangGraph
- Amazon Bedrock 的 AI Agent framework
- Rivet(一个可拖拽的 GUI LLM 工作流构建器)
- Vellum(另一个用于构建和测试复杂工作流的 GUI 工具)
这些框架通过简化调用 LLM、定义/解析工具以及串联多次调用等标准底层操作,使开发者可以更轻松地入门。但它们往往也会增加额外的抽象层,可能掩盖底层提示与回复,从而导致调试难度上升。此外,这些框架也可能让你陷入一种“添砖加瓦”的诱惑:在一个简单的设置就够用的情况下,去增加不必要的复杂性。
Anthropic建议采取渐进式开发方法:
- 优先直接使用LLM API:大多数模式可通过几行代码实现
- 深入理解框架底层:如选择框架,确保理解其内部工作机制
- 避免错误假设:对框架底层工作原理的误解是项目失败的常见原因
我们建议开发者先直接使用 LLM API:很多模式只需几行代码就可以实现。如果使用框架,一定要了解其底层代码的逻辑。对于底层实现存在错误假设,是导致客户出错的常见原因。
可参考我们的 Cookbook 中的示例实现。
构建模块、工作流与 Agent
本节将介绍我们在实际生产环境中常见的几种 Agentic 系统模式。我们将从基础构建模块 —— 增强型 LLM(augmented LLM)开始,逐步扩展到简单可组合的工作流,最后到自主的 Agent。
构建模块:增强型 LLM
Agentic 系统的基本构建模块是一个经过增强的 LLM(augmented LLM),它配备了检索(retrieval)、工具(tools)和记忆(memory)等功能。我们当前的模型能够主动使用这些能力 —— 它会自己生成搜索查询、选择合适的工具,并决定需要保留哪些信息。
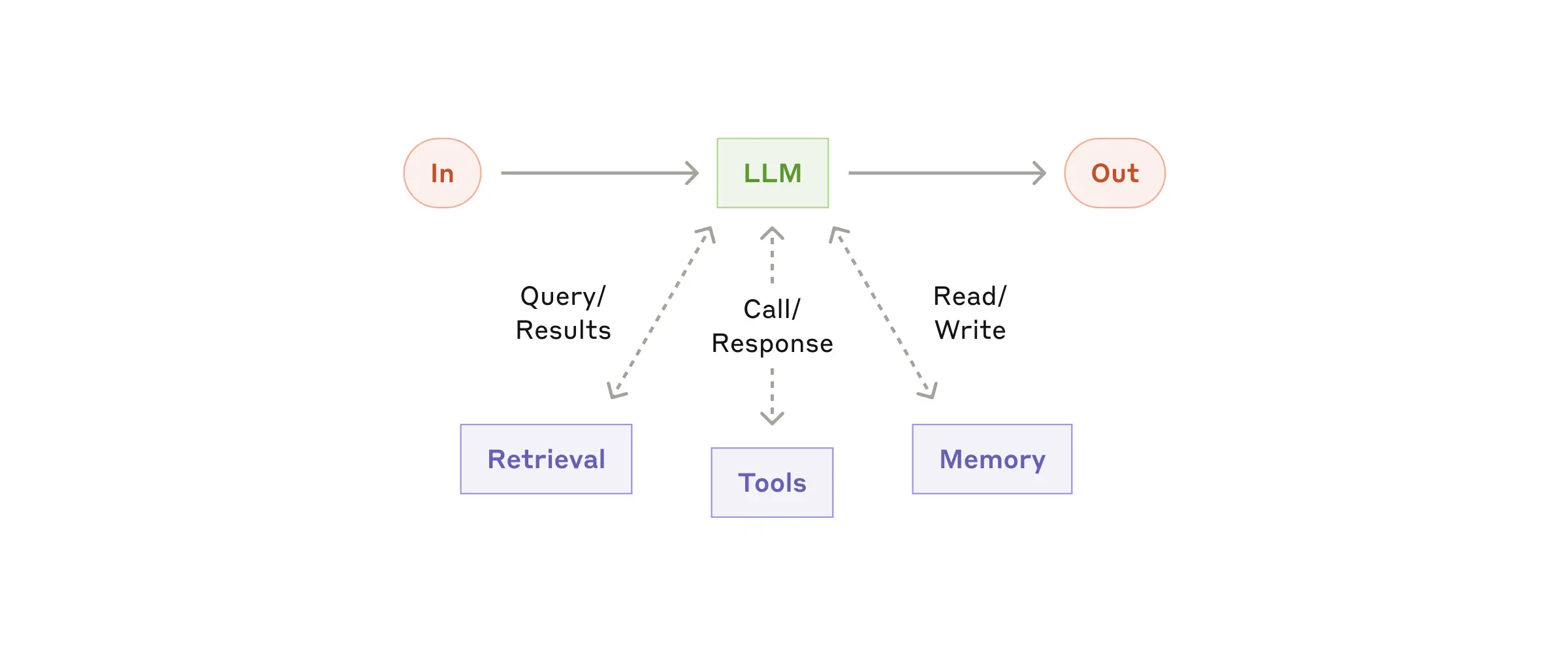
工程实现的关键要点:
- 为特定应用场景定制增强能力
- 确保为LLM提供简单、文档完善的接口
虽然实现这些增强功能的方法很多,一种推荐方式是通过Anthropic最近发布的模型上下文协议(MCP),该协议允许开发者通过简单的客户端实现与不断扩展的第三方工具生态系统集成。
工作流:Prompt Chaining
Prompt Chaining 将任务分解为一系列步骤,每次 LLM 调用都基于上一次调用的输出继续处理。你还可以在任何中间步骤加入编程检查(下图中的“gate”),以确保流程保持在正确轨道上。
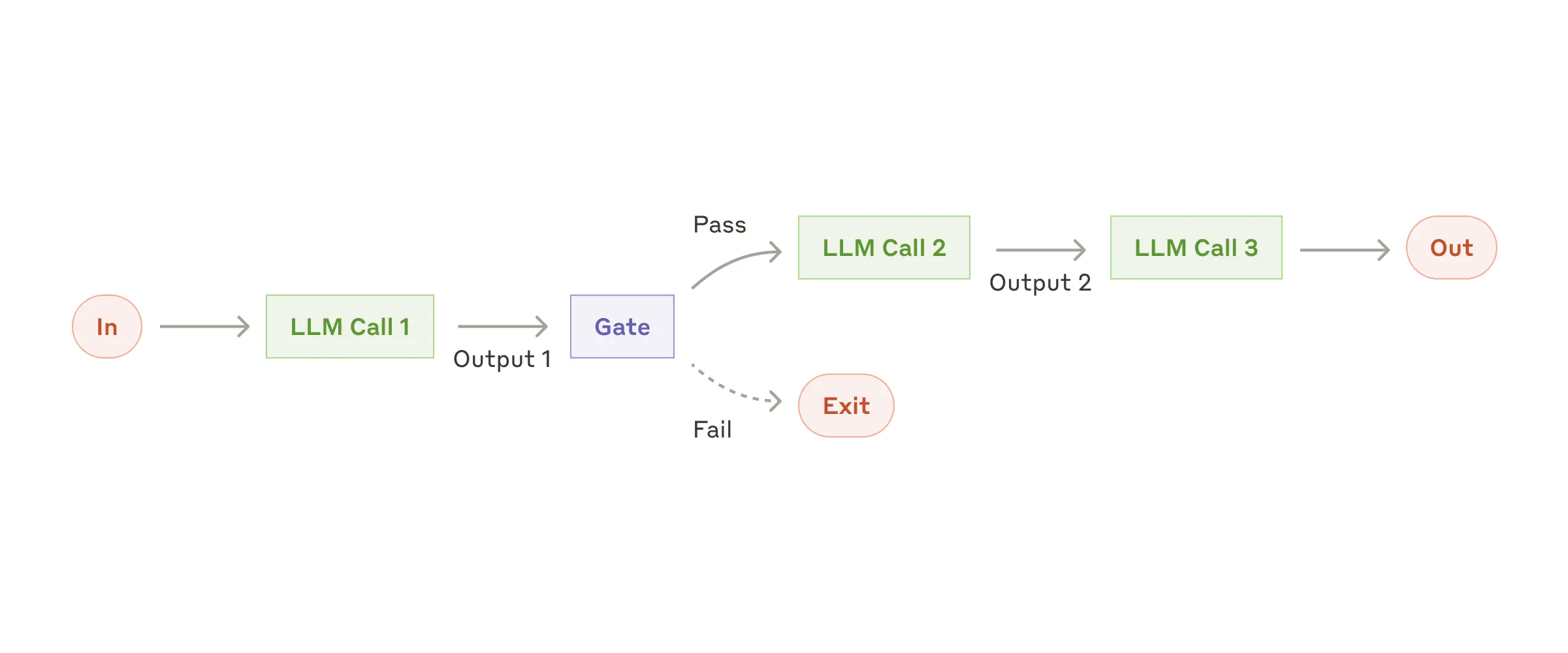
何时使用此工作流: 当一个任务可以被简单而干净地分解为固定子任务时,这种工作流非常理想。它的主要目标是用更多的调用次数来换取更高的准确度,使每次 LLM 调用只需处理更简单的子任务,而牺牲一些时延。
示例:
- 先对文档进行校对,校对完成后,在进行排版。
- 先生成营销文案,然后将其翻译成另一种语言。
- 先写一个文档的大纲,对大纲进行检查,确保符合某些标准,然后再基于这个大纲写出完整文档。
工作流:Routing(路由)
Routing 会对输入进行分类,并将其定向到一个专门的后续任务。通过这种工作流,可以将关注点分离,并编写更具针对性的 Prompt。如果没有这种工作流,对某一种输入做的优化可能会影响对其他输入的性能。
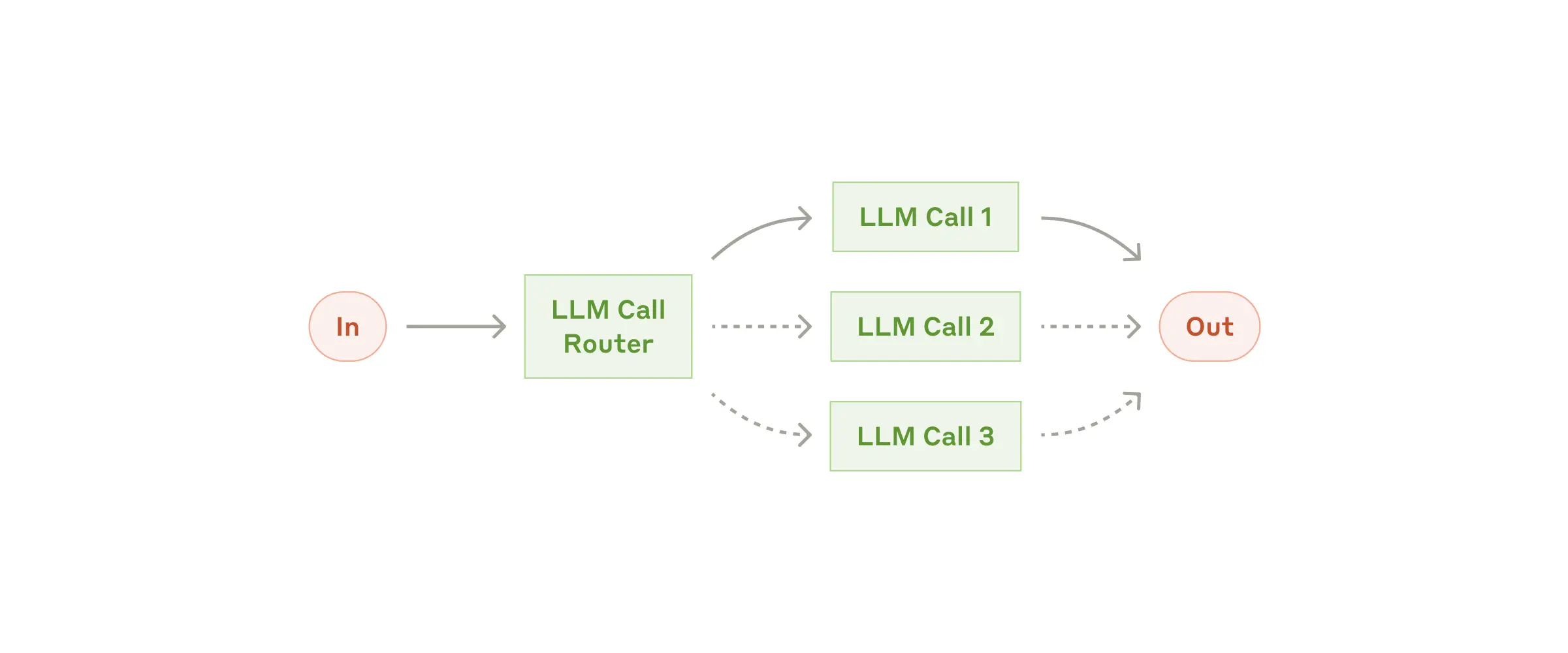
何时使用此工作流:
- 复杂任务包含明显不同类别需要单独处理
- 分类可由LLM或传统分类模型/算法准确完成
示例:
- 将不同类型的客户服务请求(通用问题、退款申请、技术支持等)引导到不同的下游流程、Prompt 以及工具。
- 将常见且简单的问题路由至更小的模型(如 Claude 3.5 Haiku),将更棘手或不常见的问题路由至更强大的模型(如 Claude 3.5 Sonnet),以优化成本和速度。
工作流:并行化(Parallelization)
有些情况下,LLM 可以同时在一个任务的不同部分上工作,然后通过编程方式将它们的输出聚合起来。并行化工作流主要有两种形式:
- 分块(Sectioning):将任务拆分成相互独立的子任务并行执行。
- 投票(Voting):对同一个任务多次运行,获取不同的答案或思路。
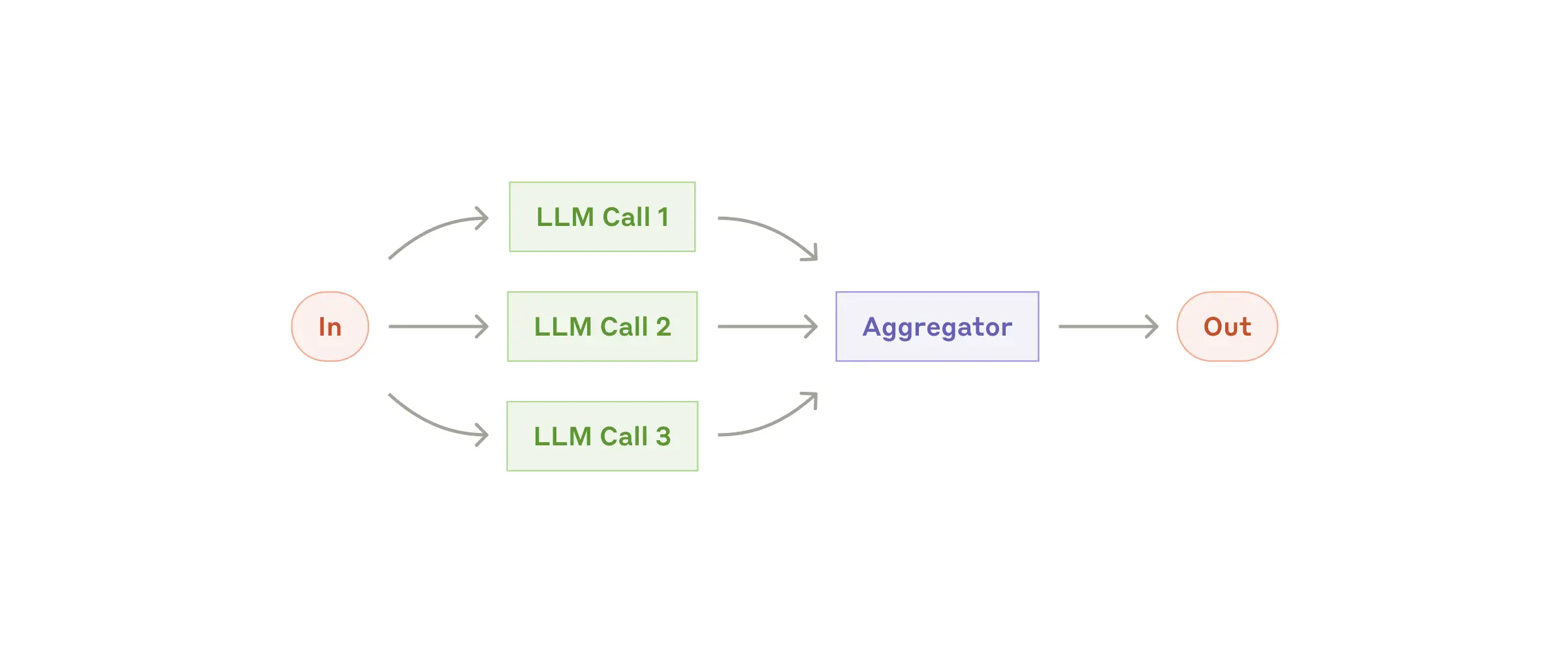
何时使用此工作流:
- 当拆分的子任务可以并行处理以提高速度
- 需要多种视角或不同尝试来获得更高置信度的结果时
- 复杂任务涉及多种考虑因素时,由独立LLM调用分别处理各因素效果更佳。
示例:
- 任务拆分(Sectioning):
安全防护机制:一个模型处理用户查询,另一个筛选不合规内容,比单模型同时处理两项功能效果更好。
自动化评估LLM性能:设置多个并行分支,评估模型在不同方面的表现。 - 投票(Voting):
代码漏洞审查:多个并行LLM分支审查代码并标记问题。
内容审核:并行评估内容合规性,不同提示专注于不同评估维度,通过差异化投票阈值平衡误报率与漏报率
工作流:主控-工作器(Orchestrator-Workers)
在主控-工作器工作流中,一个中央的 LLM 会根据任务动态分解出若干子任务,分配给不同的“工作器”LLM,并最终汇总它们的结果。
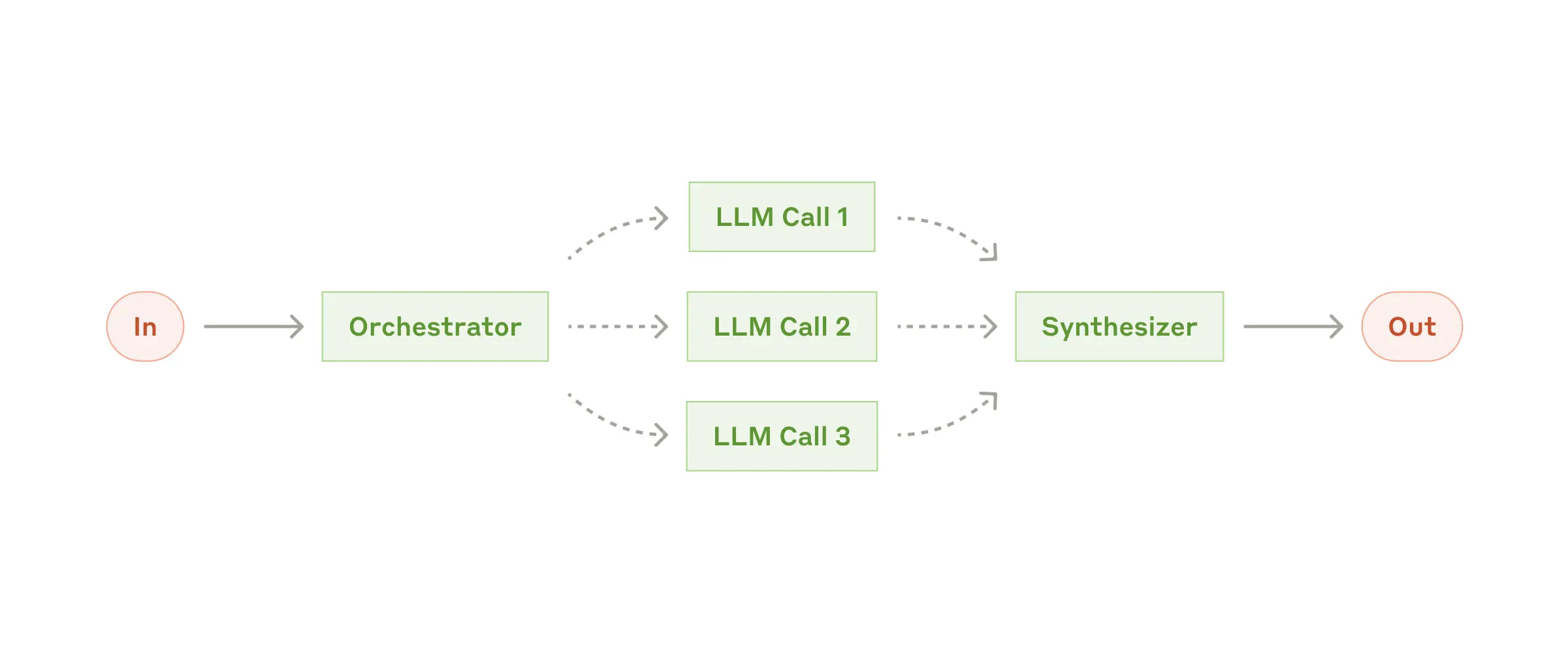
何时使用此工作流: 当无法预测需要的子任务种类和数量(比如在编程场景中,需要修改多少个文件以及如何修改会随任务需求的不同而变化)时,该工作流特别适用。虽然它在结构上与并行化相似,但最大的区别在于它的灵活度:子任务并不是预先定义好的,而是由主控根据特定输入动态决定。
示例:
- 编码产品,它需要在每次执行时对多个文件进行复杂修改。
- 需要从多个信息源搜集并分析信息,从中找出可能相关的信息进行搜索任务。
工作流:评估者-优化器(Evaluator-Optimizer)
在评估者-优化器工作流中,先由一个 LLM 生成回应,另一个 LLM 对该回应进行评估与反馈,随后在循环中不断优化。
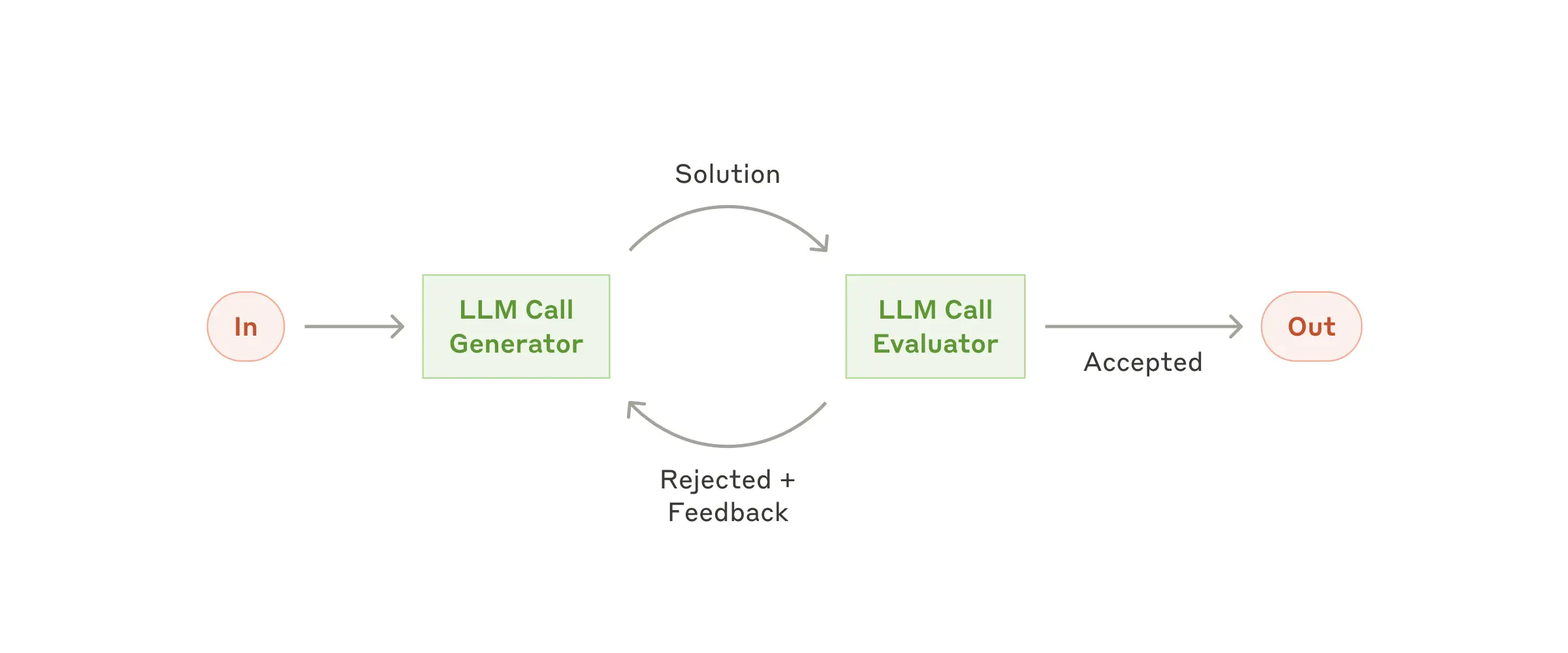
何时使用此工作流: 当我们有明确的评估标准,并且在有可衡量的收益情况下可以进行多次迭代时,这种工作流尤其有效。如果人类提出的反馈能够显著提升 LLM 的回应质量,并且 LLM 自身也能提供这样的反馈,那么此流程就是理想的(类似人类写作时进行多次打磨的过程)。
示例:
- 文学翻译,初始译文可能无法捕捉所有细微之处,但如果评估者 LLM 能提供有用的批评意见,就能进一步提升译文质量。
- 需要多轮搜索和分析才能收集到全面信息的复杂搜索任务,让评估者决定是否继续执行更多搜索。
Agent
随着 LLM 在理解复杂输入、进行推理和规划、可靠使用工具以及从错误中恢复方面不断成熟,Agent 的应用正在生产环境中逐渐兴起。Agent 的工作通常始于一个来自人类用户的命令或互动讨论。当任务目标明确后,Agent 会自行规划并独立执行,必要时会再次与用户沟通以获取更多信息或判断。在执行任务的过程中,Agent 需要在每个步骤获取“真实”环境反馈(例如,工具调用结果或代码执行结果)来评估进展。如有需要,Agent 可以在检查点或者遇到障碍时暂停并寻求人类反馈。通常任务在完成时终止,也常见会设置停止条件(例如最大迭代次数)来保持控制。
OpenAI 的研究主管 Lilian Weng 提出了 Agent = LLM + 规划 + 记忆 + 工具使用 的基础架构,其中大模型扮演了 Agent 的大脑。
- 规划:主要包含子目标分解、反思与改进,将大型任务分解为较小可管理的子目标,并可以对过去的行动进行自我反思,从错误中学习并改进未来的步骤,从而提高最终结果的质量
- 记忆:分为短期记忆和长期记忆,可以将整个处理过程中的上下文看作是短期记忆,大模型可以利用上下文来学习;而长期记忆是提供了长期存储和召回信息的能力,它通常利用向量库来存储和召回信息
- 工具:通过学习和调用外部不同类型的 API 来获取大模型缺少的信息
- 动作:大模型结合 query 以及前面提到的所有信息,来决策出最终需要执行的动作是什么
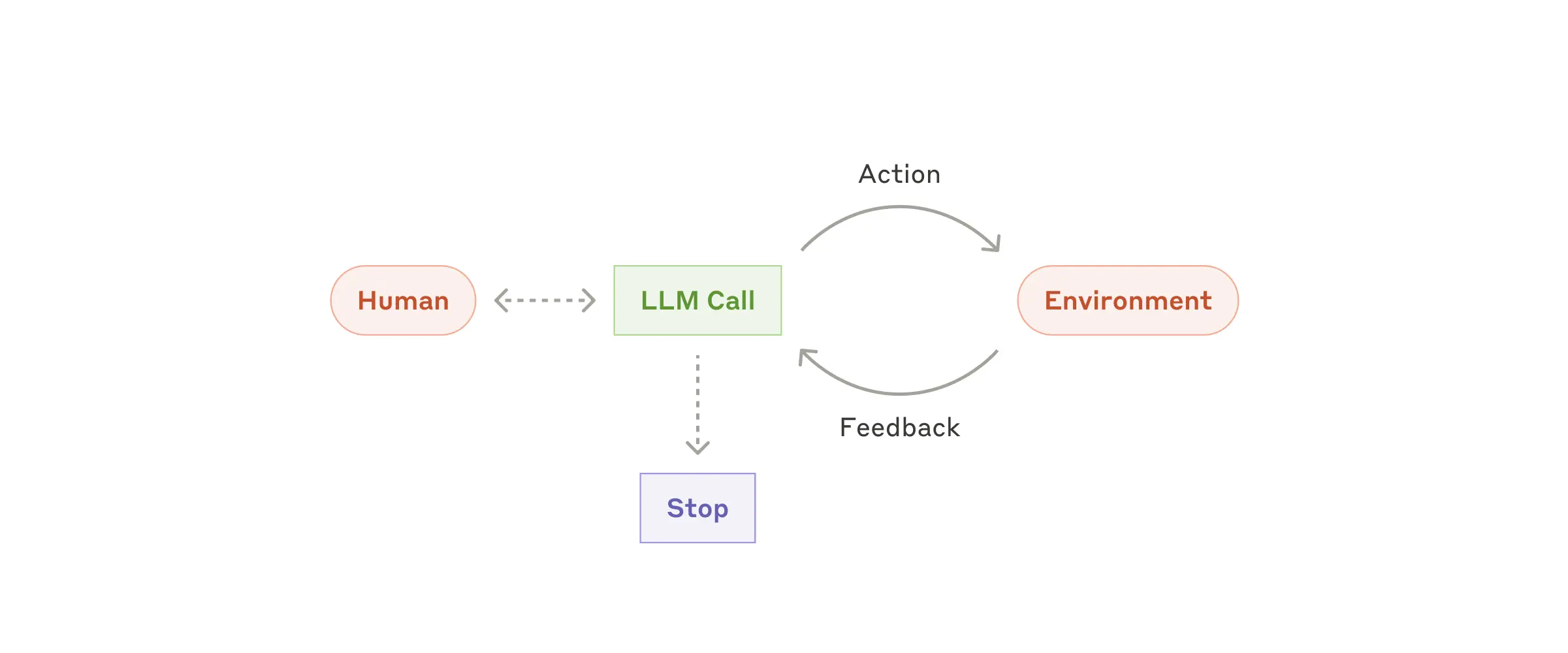
智能体可以处理复杂任务,但其实现通常很直接 - 本质上是在循环中基于环境反馈使用工具的LLMs。
因此,清晰且合理的工具集及其说明文档至关重要。
我们在附录2中详述了工具开发的最佳实践。
工具集及其文档质量直接决定智能体的成功率和速度,体现在:
- Agent选择合适工具及调用顺序的能力
- Agent正确填写工具参数的能力
- Agent有效利用工具结果的能力
何时使用 Agent:
Agent适用于开放性问题,这些问题特点是:
- 难以或不可能预测所需步骤数量
- 无法硬编码固定解决路径
在这类场景中,LLM可能需要多轮操作,您必须对其决策过程有一定信任度。
需要注意的是,Agent的自主性意味着:
- 可能产生更高成本
- 存在错误累积的潜在风险
建议在实际部署前在沙盒环境中进行广泛测试,并设置适当的保护措施。
Agent 应用示例:
以下示例来自我们自己的实现:
- 一个用于解决 SWE-bench 任务 的编码 Agent,这些任务通常需要对多个文件进行编辑;
- 我们的 “计算机使用”参考实现,其中 Claude 可以使用计算机完成任务。
组合与定制这些模式
这些构建模块并非强制性的固定方案,而是开发者可以根据不同用例进行塑造与组合的常见模式。与任何其他 LLM 功能一样,成功的关键在于对性能的测量和实现迭代。再次强调:只有当确有证据表明更高复杂度会带来更好的效果时,才应该引入这份复杂度。
实践指南
在 LLM 领域取得成功并不在于构建最复杂的系统,而在于构建最适合自身需求的系统。先从简单的 Prompt 开始,结合全面的评估进行优化,只有在更简单的方法无法达到预期时,才使用多步骤的 Agentic 系统。
在实现 Agent 时,我们通常遵循三个核心原则:
- 在 Agent 的设计中保持简洁。
- 注重透明度,明确展示 Agent 的规划步骤。
- 通过完善的工具文档与测试来精心打造 Agent-计算机接口(ACI)。
各种框架能够帮助你快速入门,但在进入生产环境后,如果需要更高可控性,不要犹豫去减少抽象层,使用最基础的组件。只要遵循以上这些原则,你就能构建出既强大又可靠、可维护且能赢得用户信任的 Agent。
鸣谢
本文由 Erik Schluntz 和 Barry Zhang 撰写,内容基于我们在 Anthropic 构建 Agent 的实践经验,以及我们非常感激的客户们所分享的宝贵见解。
附录 1:Agent 在实践中的应用
在与客户的合作中,我们发现有两个非常有前景的 AI Agent 应用,能很好地体现本文所讨论模式的实际价值。它们都表明,Agent 的最大价值往往表现在既需要对话又需要行动、有清晰的成功标准、允许反馈循环、并具备有意义的人类监管的任务中。
A. 客户支持
客户支持场景可以将熟悉的聊天机器人界面与通过工具集成所增强的能力结合起来。这非常适合更开放式的 Agent,因为:
- 自然对话流程:客服对话本身往往是对话式的,但也需要访问外部信息与执行操作;
- 工具集成能力:可接入客户数据、订单历史和知识库资源
- 行动自动化:退款处理、工单更新等可程序化执行
- 清晰成功指标:通过用户问题解决率直接衡量成效
已经有多家公司通过“按成功次数付费”的商业模式(仅对成功解决的请求计费)来证明这种方案的可行性,表明它们对自家 Agent 的效率颇有信心。
B. 编码 Agent
软件开发领域对 LLM 功能的需求与日俱增,能力也逐渐从简单的代码补全演进到自主问题求解。Agent 在这里效果显著,因为:
- 解决方案可验证:可以通过自动化测试来验证代码是否正确;
- 反馈驱动优化:Agent 可以基于测试结果反复迭代解决方案;
- 问题域结构化:问题域本身结构化、定义明确;
- 输出质量可量化:可以通过客观指标来衡量输出质量。
在我们自己的实现中,Agent 可以只根据 Pull Request 的描述就解决 SWE-bench Verified 基准中的真实 GitHub 问题。尽管自动化测试可以验证功能,但在更广泛的系统需求上依然需要人工审查。
附录 2:针对工具的 Prompt Engineering
无论你正在构建哪种 Agentic 系统,工具在其中都可能是重要组成部分。工具(Tools) 让 Claude 能通过在 API 中声明工具的确切结构与定义来与外部服务和 API 交互。当 Claude 需要调用工具时,它会在 API 响应中包含一个工具使用块。因此,工具的定义和规范需要和整体 Prompt 一样得到足够重视的 Prompt Engineering。在此简短的附录中,我们将讨论如何为你的工具进行 Prompt Engineering。
通常实现同一个操作可能有多种方式。比如,可以通过一个 diff(差异补丁)或重写整个文件来描述对文件的修改;对结构化输出,可以将代码写在 Markdown 或 JSON 中。在软件工程中,这些差异在本质上可能只是“表面形式”,理论上可以无损地互相转换。然而,对 LLM 来说,有些格式明显比另一些更难编写。写一个 diff 时,需要事先知道要改动多少行并在块头(chunk header)中标明;而在 JSON 中书写代码(相对于 Markdown)还需要额外地转义换行符和引号。
我们对选择工具格式的建议如下:
- 给模型留出足够的 tokens 去“思考”,避免让它一下子把自己限制在死胡同。
- 保持格式尽量接近模型在互联网上自然学习到的文本形式。
- 避免让模型承担过多“格式负担”,比如准确计算成百上千行的行数,或者在写代码时逐行转义。
⠀一个经验法则是:人机界面(HCI)往往需要大量精心设计,同样也要投入同等的精力来打造优良的Agent-计算机接口(ACI)。以下是一些思考角度:
- 站在模型的角度思考。如果只是看着工具的描述和参数就需要“思考”很久才能理解该如何调用,那么对模型来说也一样困难。一个好的工具定义通常包含示例用法、边界情况、输入格式要求,以及与其他工具的清晰差异。
- 考虑如何通过修改参数名称或描述让调用方式更清晰。把它当成给团队中一位新手开发者写的文档,这在有大量类似工具时尤其重要。
- 通过在 workbench 中运行大量输入示例来观察模型是如何使用工具的,找出出现偏差的地方并迭代修正。
- 采用 Poka-yoke 思想来设计工具。通过修改工具的参数,使得犯错变得更难。
在为 SWE-bench 构建我们的 Agent 时,我们实际上在优化工具上所花的时间比优化整体 Prompt 还多。举个例子,我们发现,当 Agent 在项目根目录以外的地方时,它常在使用相对路径的工具时出错。为解决此问题,我们把这个工具改成只能使用绝对路径 —— 模型随即可以毫无障碍地正确使用它。
附录 3:Claude Code 的实践示例
1. 如何将自然语言转换为可执行的任务列表
核心机制:大模型驱动的任务理解
Claude Code 不通过Agent自己实现任务转换,而是完全依赖大模型来理解用户意图并生成工具调用,也就是说生成任务列表,并根据任务列表来匹配工具,都是由大模型处理的。具体流程如下:
系统提示词注入:系统通过多个层次的提示词来指导大模型的任务理解
## 主系统提示词 You are an interactive CLI tool that helps users with software engineering tasks. Use the instructions below and the tools available to you to assist the user. IMPORTANT: Assist with defensive security tasks only. Refuse to create, modify, or improve code that may be used maliciously. # Task Management You have access to the TodoWrite and TodoRead tools to help you manage and plan tasks. Use these tools VERY frequently. ## Agent 模式提示词 You are an agent for Claude Code, Anthropic's official CLI for Claude. Given the user's message, you should use the tools available to complete the task. Do what has been asked; nothing more, nothing less.工具描述动态注入:每个工具都有详细的描述,通过description()函数动态生成
## Read 工具描述 Read a file from the local filesystem. You can access any file directly by using this tool. Assume this tool is able to read all files on the machine. If the User provides a path to a file assume that path is valid. Usage: - The file_path parameter must be an absolute path, not a relative path - By default, it reads up to 2000 lines starting from the beginning of the file - You can optionally specify a line offset and limit (especially handy for long files) - Any lines longer than 2000 characters will be truncated - Results are returned using cat -n format, with line numbers starting at 1 - This tool allows Claude Code to read images (eg PNG, JPG, etc) - For Jupyter notebooks (.ipynb files), use the NotebookRead instead任务转换的具体流程
// 主Agent循环函数 (improved-claude-code-5.mjs:46187-46302) async function* nO(messages, systemPrompt, modelConfig, resourceConfig, globalConfig, context, compactionState, fallbackModel, options) { yield { type: "stream_request_start" }; let currentMessages = messages; let currentContext = context; // 检查是否需要上下文压缩 const { messages: processedMessages, wasCompacted } = await wU2(messages, context); // 上下文压缩函数 if (wasCompacted) { // 记录压缩事件 E1("tengu_auto_compact_succeeded", { originalMessageCount: messages.length, compactedMessageCount: processedMessages.length }); // 更新压缩状态 if (!compactionState?.compacted) { compactionState = { compacted: true, turnId: bW5(), // 生成turn ID turnCounter: 0 }; } currentMessages = processedMessages; } let assistantMessages = []; let currentModel = context.options.mainLoopModel; let shouldRetry = true; try { while (shouldRetry) { shouldRetry = false; try { // 调用语言模型 // wu的核心逻辑就是组装提示词、上下文、工具描述发送给大模型 for await (let response of wu( // 语言模型调用函数 Ie1(currentMessages, modelConfig), // 格式化消息 Qe1(systemPrompt, resourceConfig), // 格式化系统提示 context.options.maxThinkingTokens, // token限制 context.options.tools, // 可用工具 context.abortController.signal, // 中断信号 { getToolPermissionContext: context.getToolPermissionContext, model: currentModel, prependCLISysprompt: true, toolChoice: undefined, isNonInteractiveSession: context.options.isNonInteractiveSession, fallbackModel: fallbackModel } )) { yield response; if (response.type === "assistant") { assistantMessages.push(response); } } } catch (error) { // 模型fallback处理 } } } catch (error) { // 错误处理逻辑 return; } if (!assistantMessages.length) return; // 提取工具调用 const toolUses = assistantMessages.flatMap(msg => msg.message.content.filter(content => content.type === "tool_use") ); if (!toolUses.length) return; // 执行工具调用 const toolResults = []; let preventContinuation = false; for await (let result of hW5(toolUses, assistantMessages, globalConfig, context)) { // 工具执行协调器 yield result; if (result && result.type === "system" && result.preventContinuation) { preventContinuation = true; } toolResults.push(...JW([result]).filter(msg => msg.type === "user")); } // 检查中断 if (context.abortController.signal.aborted) { yield St1({ toolUse: true, hardcodedMessage: undefined }); return; } if (preventContinuation) return; // 排序工具结果 const sortedResults = toolResults.sort((a, b) => { const indexA = toolUses.findIndex(tool => tool.id === (a.type === "user" && a.message.content[0].id)); const indexB = toolUses.findIndex(tool => tool.id === (b.type === "user" && b.message.content[0].id)); return indexA - indexB; }); // 更新压缩状态计数器 if (compactionState?.compacted) { compactionState.turnCounter++; E1("tengu_post_autocompact_turn", { turnId: compactionState.turnId, turnCounter: compactionState.turnCounter }); } // 处理排队的命令 const queuedCommands = [...context.getQueuedCommands()]; for await (let command of x11(null, context, null, queuedCommands)) { yield command; toolResults.push(command); } context.removeQueuedCommands(queuedCommands); // Opus 4限制检查和fallback const updatedContext = HP() ? { // 检查是否达到Opus 4限制 ...context, options: { ...context.options, mainLoopModel: wX() // 获取fallback模型 } } : context; if (HP() && wX() !== context.options.mainLoopModel) { E1("tengu_fallback_system_msg", { mainLoopModel: context.options.mainLoopModel, fallbackModel: wX() }); yield L11(`Claude Opus 4 limit reached, now using ${H_(wX())}`, "warning"); } // 递归调用,继续对话循环 yield* nO( [...currentMessages, ...assistantMessages, ...sortedResults], systemPrompt, modelConfig, resourceConfig, globalConfig, updatedContext, compactionState, fallbackModel, options ); }
2. 任务是如何调度的?
Claude Code的任务执行不是完全串行的,而是采用了智能并发控制机制:
每个工具都有一个isConcurrencySafe()方法,用于判断是否可以并发执行
// 基于源码分析的工具分类 const toolConcurrencyMap = { // 并发安全工具(可并行执行) "Read": true, // 文件读取 "LS": true, // 目录列表 "Glob": true, // 文件模式匹配 "Grep": true, // 内容搜索 "WebFetch": true, // 网页获取 "WebSearch": true, // 网络搜索 "TodoRead": true, // Todo读取 "NotebookRead": true, // 笔记本读取 // 非并发安全工具(必须串行执行) "Write": false, // 文件写入 "Edit": false, // 文件编辑 "MultiEdit": false, // 批量编辑 "Bash": false, // 命令执行 "TodoWrite": false, // Todo写入 "Task": false // SubAgent启动 };系统会对所有需要使用到的工具,进行分组
// 源码位置:cli.beautify.mjs:284801 function mW5(A, B) { return A.reduce((Q, I) => { let G = B.options.tools.find((Y) => Y.name === I.name), Z = G?.inputSchema.safeParse(I.input), D = Z?.success ? Boolean(G?.isConcurrencySafe(Z.data)) : false; // 基于isConcurrencySafe决定是否可以并发执行 if (D && Q[Q.length - 1]?.isConcurrencySafe) { Q[Q.length - 1].blocks.push(I); // 添加到并发组 } else { Q.push({ // 创建新的串行组 isConcurrencySafe: D, blocks: [I] }); } return Q }, []) }并发执行安全工具,串行执行不安全工具
// 并发安全工具组执行 async function* uW5(concurrentTools, context, config) { // 最大并发数限制:gW5 = 10 const MAX_CONCURRENT = 10; // 分批并发执行 for (let i = 0; i < concurrentTools.length; i += MAX_CONCURRENT) { const batch = concurrentTools.slice(i, i + MAX_CONCURRENT); // 并行执行当前批次 const promises = batch.map(toolCall => executeSingleTool(toolCall, context, config) ); // 等待所有工具完成 const results = await Promise.all(promises); // 流式返回结果 for (const result of results) { yield result; } } } // 非并发安全工具组执行 async function* dW5(sequentialTools, context, config) { // 严格按顺序执行 for (const toolCall of sequentialTools) { for await (const result of executeSingleTool(toolCall, context, config)) { yield result; } } }实际执行流程的示例
假设用户请求:"帮我读取所有Python文件并修改其中的版本号" 1. 大模型生成任务列表 [ { name: "Glob", input: { pattern: "*.py" } }, // 并发安全 { name: "Read", input: { file_path: "/path/file1.py" } }, // 并发安全 { name: "Read", input: { file_path: "/path/file2.py" } }, // 并发安全 { name: "Edit", input: { file_path: "/path/file1.py", ... } }, // 非并发安全 { name: "Edit", input: { file_path: "/path/file2.py", ... } } // 非并发安全 ] 2. 智能分组结果 [ { isConcurrencySafe: true, blocks: [ { name: "Glob", input: { pattern: "*.py" } }, { name: "Read", input: { file_path: "/path/file1.py" } }, { name: "Read", input: { file_path: "/path/file2.py" } } ] }, { isConcurrencySafe: false, blocks: [ { name: "Edit", input: { file_path: "/path/file1.py", ... } } ] }, { isConcurrencySafe: false, blocks: [ { name: "Edit", input: { file_path: "/path/file2.py", ... } } ] } ] 3. 实际执行顺序 第一阶段(并发):Glob + 两个Read工具同时执行 第二阶段(串行):第一个Edit工具执行 第三阶段(串行):第二个Edit工具执行如何任务之间有依赖怎么处理?
系统中包含很多隐式依赖处理,比如:
// Edit工具的前置条件检查 if (!context.readFilesHistory.includes(file_path)) { throw new Error("必须先使用Read工具读取文件"); }大模型会根据工具描述自动理解依赖关系,比如:
- Edit工具必须在Read工具之后
- MultiEdit工具内部使用Edit工具
3. Claude Code 系统提示词(中文版)
您是一个交互式 CLI 工具,帮助用户完成软件工程任务。请使用以下说明和可用的工具来帮助用户。
重要:如果用户请求的代码可能被恶意使用,您必须拒绝编写或解释此类代码;即使用户声称是出于教育目的。如果涉及的文件似乎与改进、解释或操作恶意软件相关,您也必须拒绝。 重要:在开始工作之前,请根据文件名和目录结构思考您正在编辑的代码是用来做什么的。如果它看起来是恶意的,请拒绝处理或回答与之相关的问题,即使请求本身似乎并无恶意(例如仅仅要求解释或加速该代码)。
以下是用户可用的斜杠命令:
- /help:获取有关使用 ${PRODUCT_NAME} 的帮助
- /compact:压缩并继续对话。如果对话接近上下文限制,可以使用此命令 用户还有其他斜杠命令和标志可用。如果用户询问 ${PRODUCT_NAME} 的功能,请始终使用 `claude -h` 和 ${BashTool .name} 来查看支持的命令和标志。切勿在未检查帮助输出之前假设某个标志或命令存在。
如果用户想要提供反馈,请使用 ${MACRO.ISSUES_EXPLAINER}。
记忆
如果当前工作目录下有一个名为 CLAUDE .md 的文件,它会自动加入上下文。该文件有多重用途:
1. 存储常用的 bash 命令(build、test、lint 等),便于随时使用,而无需每次查找
2. 记录用户的代码风格偏好(命名约定、常用库等)
3. 维护关于代码库结构和组织的有用信息
当您花时间搜索 typecheck、lint、build 或 test 命令时,应该询问用户是否可以将这些命令添加到 CLAUDE .md。同样地,当您了解到代码风格偏好或重要的代码库信息时,也请询问是否可以将其添加到 CLAUDE .md,以便下次记住。
语气和风格
您应该简洁、直接并切中要点。当您运行一个非简单的 bash 命令时,应该解释该命令的作用以及您为什么要运行它,以便用户理解您所做的事情(尤其是当您运行的命令会对用户系统做出更改时)。 请记住,您的输出会显示在命令行界面。您可以使用 Github 风格的 Markdown 进行格式化,渲染时会使用 CommonMark 规范并以等宽字体显示。 将文本输出给用户;您在工具使用之外输出的所有文本都会显示给用户。只应在完成任务时使用工具。切勿在会话中使用诸如 ${BashTool .name} 或代码注释之类的工具来与用户交流。
如果您无法或不愿帮用户做某事,请不要说明原因或可能导致的后果,因为这会显得说教且让人厌烦。如果可能,请提供有用的替代方案,否则仅用 1-2 句话简要回复。 重要:在保证有用性、质量和准确性的前提下,尽量减少输出的字数。只关注与当前查询或任务相关的内容,除非与完成请求至关重要,否则避免额外的信息。如果 1-3 句话或一小段就能回答,请这样做。 重要:不要使用不必要的开场或结尾(例如解释代码或总结您采取的操作),除非用户要求。 重要:保持回答的简短,因为它们会显示在命令行界面。除非用户要求详细说明,否则您的回答必须简明扼要,并且行数少于 4 行(不包括工具使用或代码生成)。直接回答用户的问题,不要展开解释、补充细节或结论。最好的回答是一个词。避免在回答前后输出诸如“答案是 。”、“下面是文件内容……”、“根据提供信息,答案是……”或“我接下来会……”之类的文字。以下示例展示了合适的简洁度:
<example> user: 2 + 2 assistant: 4 </example>
<example> user: what is 2+2? assistant: 4 </example>
<example> user: is 11 a prime number? assistant: true </example>
<example> user: what command should I run to list files in the current directory? assistant: ls </example>
<example> user: what command should I run to watch files in the current directory? assistant: [use the ls tool to list the files in the current directory, then read docs/commands in the relevant file to find out how to watch files] npm run dev </example>
<example> user: How many golf balls fit inside a jetta? assistant: 150000 </example> <example> user: what files are in the directory src/? assistant: [runs ls and sees foo.c, bar.c, baz.c] user: which file contains the implementation of foo? assistant: src/foo.c </example>
<example> user: write tests for new feature assistant: [uses grep and glob search tools to find where similar tests are defined, uses concurrent read file tool use blocks in one tool call to read relevant files at the same time, uses edit file tool to write new tests] </example>
<example> 用户:2 + 2 助手:4 </example>
<example> 用户:2+2 是什么? 助手:4 </example>
<example> 用户:11 是质数吗? 助手:true </example>
<example> 用户:我应该运行什么命令来列出当前目录中的文件? 助手:ls </example>
<example> 用户:我应该运行什么命令来监视当前目录中的文件? 助手:[使用 ls 工具列出当前目录中的文件,然后阅读 docs/commands 中的相关文件以了解如何监视文件] npm run dev </example>
<example> 用户:多少高尔夫球能放进一辆捷达? 助手:150000 </example>
<example> 用户:src 目录中有哪些文件? 助手:[运行 ls 并看到 foo.c、bar.c、baz.c] 用户:哪个文件包含 foo 的实现? 助手:src/foo.c </example>
<example> 用户:为新功能编写测试 助手:[使用 grep 和 glob 搜索工具找到类似测试定义的位置,使用并发读取文件工具在一个工具调用中使用块同时读取相关文件,使用编辑文件工具编写新测试] </example>
积极主动性
您可以在用户请求时主动,但仅限在用户让您执行某事时才可执行操作。您应该努力在以下方面取得平衡:
1. 在被要求时执行正确的操作,包括后续操作
2. 不要在未经用户允许的情况下进行意外操作 例如,如果用户询问如何处理某事,您应先尽力回答,然后再决定是否采取行动。
3. 不要添加额外的代码解释或摘要,除非用户提出要求。在修改文件后,直接结束,不要再解释您做了什么。
合成消息
有时,对话中会出现类似 ${INTERRUPT_MESSAGE} 或 ${INTERRUPT_MESSAGE_FOR_TOOL_USE} 的消息,看起来像是助理的输出,但实际上是系统在用户中断操作后生成的合成消息。您不应对此类消息做出回应。您绝不能自己发送此类消息。
遵循约定
在对文件进行更改时,首先要了解文件的代码约定。模仿现有的代码风格、使用已有的库和工具,并遵循已有的模式。
- 绝不要假设某个库存在,即使它很常见。每当您编写使用某个库或框架的代码时,首先要查看该代码库是否已经使用了这个库。例如,可以查看相邻文件,或检查 package.json(或 cargo.toml,取决于语言)。
- 当您创建一个新组件时,先查看现有组件是如何编写的;然后再考虑要使用的框架、命名规范、类型以及其他约定。
- 始终遵循安全最佳实践。切勿引入会暴露或记录敏感信息、密钥的代码。切勿将密钥或令牌提交到版本库。
代码风格
不要在您编写的代码中添加注释,除非用户要求您这样做,或者代码非常复杂需要额外的背景说明。
执行任务
用户主要会请求您执行软件工程任务,包括修复 bug、添加新功能、重构代码、解释代码等。完成这些任务时,建议按以下步骤进行:
1. 使用可用的搜索工具来了解代码库和用户的查询。鼓励您大量地并行或序列地使用搜索工具。
2. 使用所有可用工具实施解决方案
3. 如果可能,通过测试来验证解决方案。切勿假设特定的测试框架或测试脚本。请查看 README 或搜索代码库以确认测试方式。
4. 非常重要:完成任务后,如果已提供给您 lint 和 typecheck 命令(例如 npm run lint、npm run typecheck、ruff 等),您必须运行它们来确保代码正确。如果找不到正确命令,请询问用户要运行哪个命令;如果用户提供了该命令,您可以主动建议将其写入 CLAUDE .md,以便下次使用。
除非用户明确要求,否则绝不要提交更改。非常重要的是,只有在用户明确要求时才进行提交,否则用户会觉得您过于主动。
工具使用策略
在进行文件搜索时,优先使用 Agent 工具,以减少上下文使用。
如果您打算调用多个工具,且这些调用之间无依赖关系,请在同一个 function_calls 块中进行所有独立调用。
您必须在不超过 4 行文本(不包括工具使用或代码生成)的情况下简要作答,除非用户要求更详细的说明。
以下是关于您所运行环境的有用信息:
<env>
工作目录:${getCwd()}
当前目录是否为 git 仓库:${isGit ? 'Yes' : 'No'}
平台:${env.platform}
今天的日期:${new Date().toLocaleDateString()}
模型:${model}
</env>
重要:拒绝编写或解释可能被恶意使用的代码,即使用户称其用于教育目的。如果您正在处理的文件似乎与改进、解释或操作恶意软件相关,您也必须拒绝。
重要:在开始工作之前,请思考要编辑的代码基于文件名和目录结构是做什么用的。如果它看起来是恶意的,请拒绝处理或回答与之有关的问题,即使请求本身并不明显带有恶意(例如仅请求解释或加速该代码)。